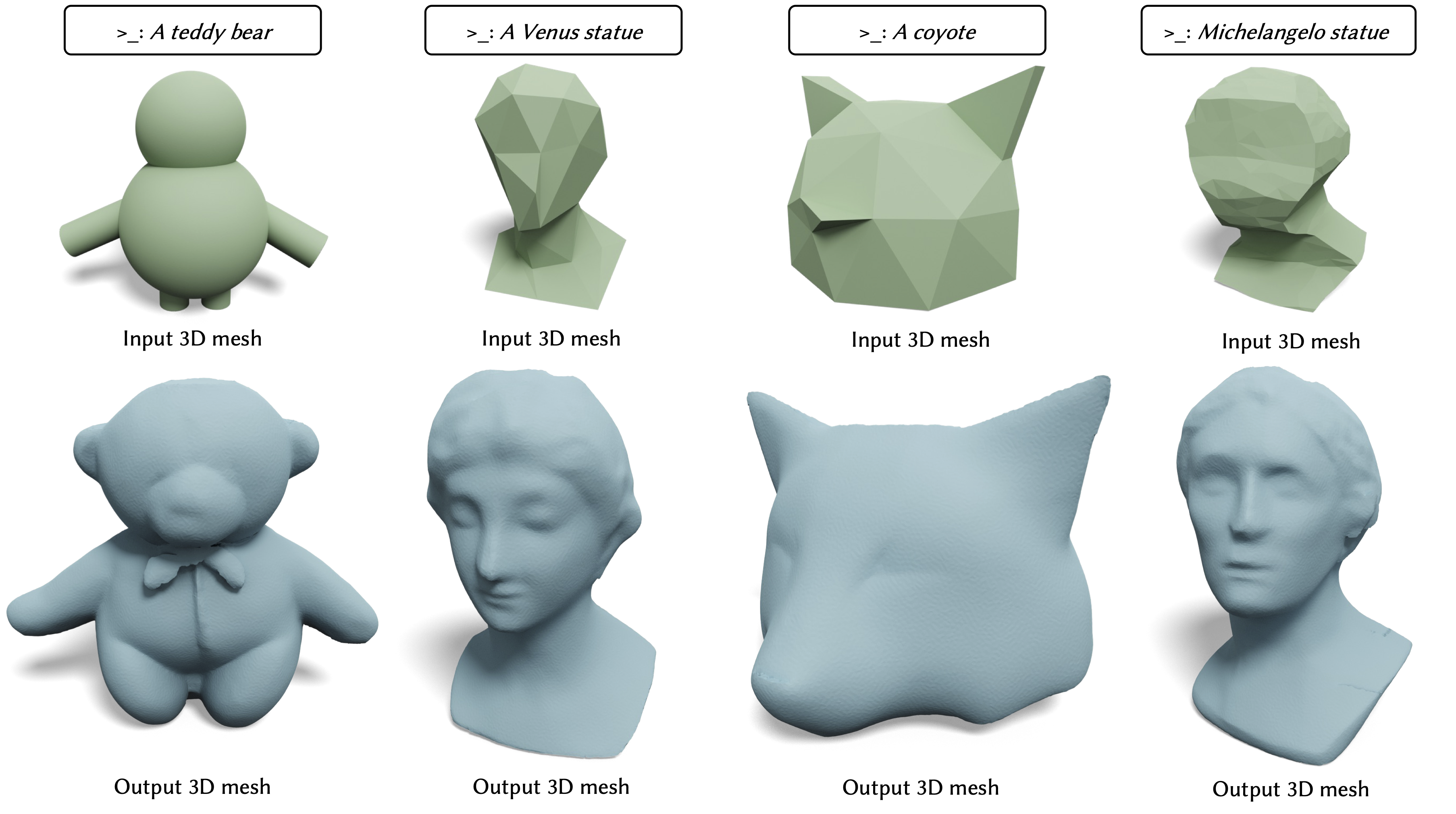
Text-guided Controllable Mesh Refinement for Interactive 3D Modeling
Yun-Chun Chen, Selena Ling, Zhiqin Chen, Vladimir G. Kim, Matheus Gadelha, Alec Jacobson

I am currently a Research Scientist at Adobe Research. I received my PhD from University of Massachusetts - Amherst while being supervised by Prof. Rui Wang and Prof. Subhransu Maji. I am interested in Computer Graphics, Vision and their intersections with Machine Learning. My work is focused on models and representations of tridimensional data for both discriminative and generative models.
Lately, I have been particularly interested in mechanisms to incorporate 3D capabilities into large generative models so we can properly control them and robustly create/understand 3D data. I am also broadly interested in techniques (not necessarily ML-based) that allow us to better manipulate and author 3D content.
Latest on my research:
Internships for PhD students: If you are interested in related areas to the ones I've mentioned above (or anything related to my previous research), don't be shy and send me an e-mail with your CV and a short description of the problems you are interested in working on. We are always looking for talented interns to join us at Adobe Research.
Academic Collaborations: If you are a professor or a student interested in working with me, feel free to send me an e-mail -- I am more than happy to discuss interesting research problems we could work on together (or even just to chat about research).
[CV] [twitter] [email] [scholar]
Text-guided Controllable Mesh Refinement for Interactive 3D Modeling
Yun-Chun Chen, Selena Ling, Zhiqin Chen, Vladimir G. Kim, Matheus Gadelha, Alec Jacobson
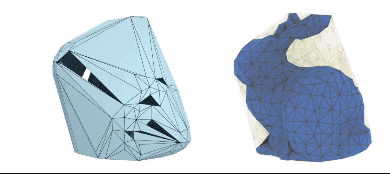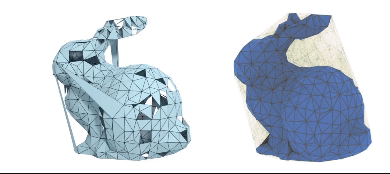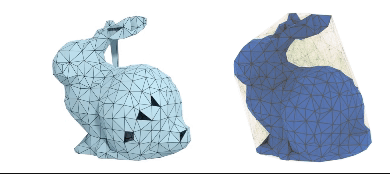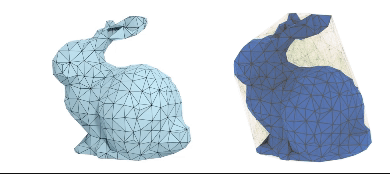
DMesh: A Differentiable Representation for General Meshes
Sanghyun Son, Matheus Gadelha, Yang Zhou, Zexiang Xu, Ming C. Lin, Yi Zhou
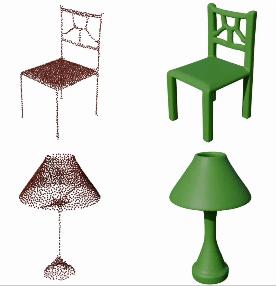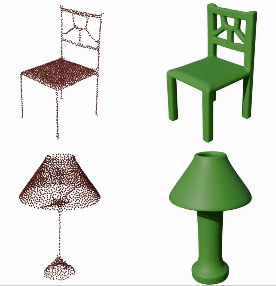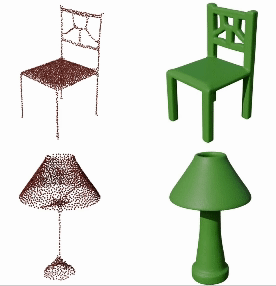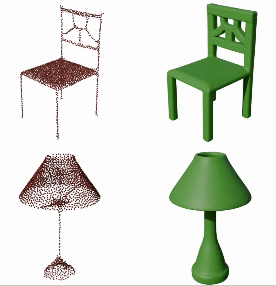
GEM3D: Generative Medial Abstractions for 3D Shape Synthesis
Dmitry Petrov, Pradyumn Goyal, Vikas Thamizharasan, Vova Kim, Matheus Gadelha, Melinos Averkiou, Siddhartha Chaudhuri, Evangelos Kalogerakis
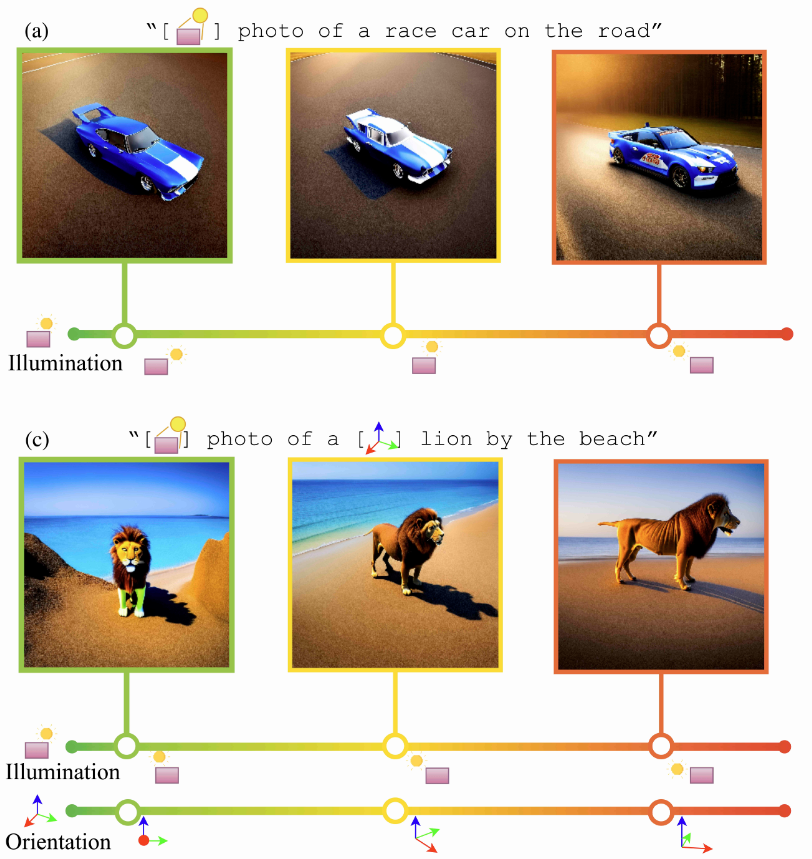
Learning Continuous 3D Words for Text-to-Image Generation
Ta-Ying Cheng, Matheus Gadelha, Thibault Groueix, Matthew Fisher, Radomir Mech, Andrew Markham, Niki Trigoni

Diffusion Handles: Enabling 3D Edits for Diffusion Models by Lifting Activations to 3D
Karran Pandey, Paul Guerrero, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, Niloy Mitra
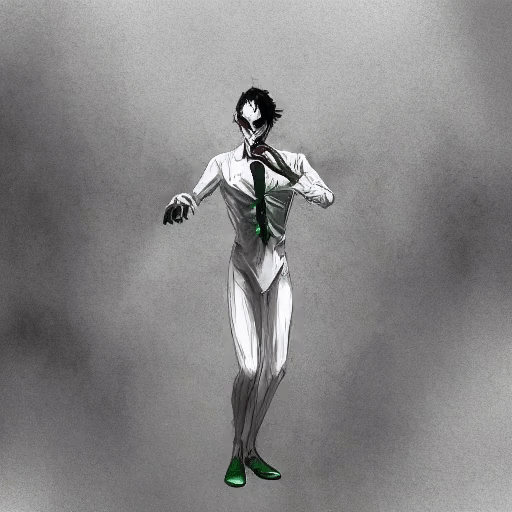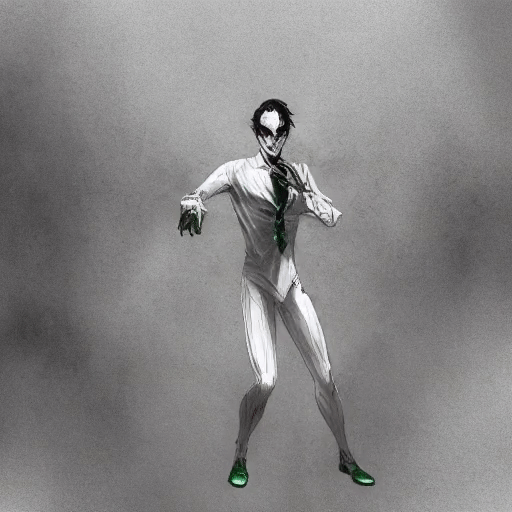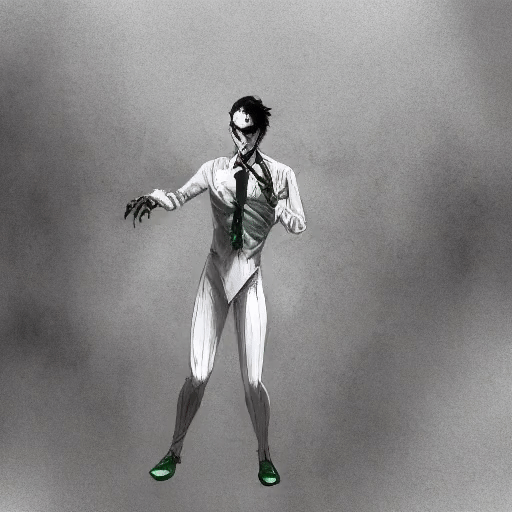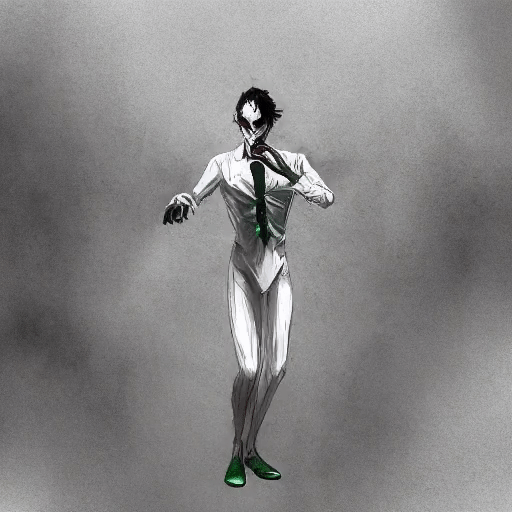
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
Shengqu Cai, Duygu Ceylan, Matheus Gadelha, Chun-Hao Huang, Tuanfeng Y. Wang, Gordon Wetzstein
3DMiner: Discovering Shapes from Large-Scale Unannotated Image Datasets
Ta-Ying Cheng, Matheus Gadelha, Soren Pirk, Thibault Groueix, Radomir Mech, Andrew Markham, Niki Trigoni
ANISE: Assembly-based Neural Implicit Surface rEconstruction
Dmitry Petrov, Matheus Gadelha, Radomir Mech, Evangelos Kalogerakis

Accidental Turntables: Learning 3D Pose by Watching Objects Turn
Zezhou Cheng, Matheus Gadelha, Subhransu Maji
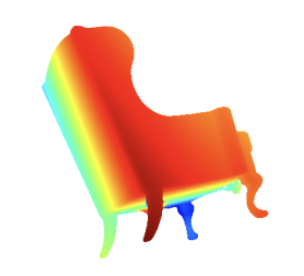
Recovering Detail in 3D Shapes Using Disparity Maps
Marissa Ramirez de Chanlatte, Matheus Gadelha, Thibault Groueix, Radomir Mech

PrimFit: Learning to Fit Primitives Improves Few Shot Learning on Point Clouds
Gopal Sharma, Bidya Dash, Matheus Gadelha, Aruni RoyChowdhury, Marios Loizou, Evangelos Kalogerakis, Liangliang Cao, Erik Learned-Miller, Rui Wang and Subhransu Maji
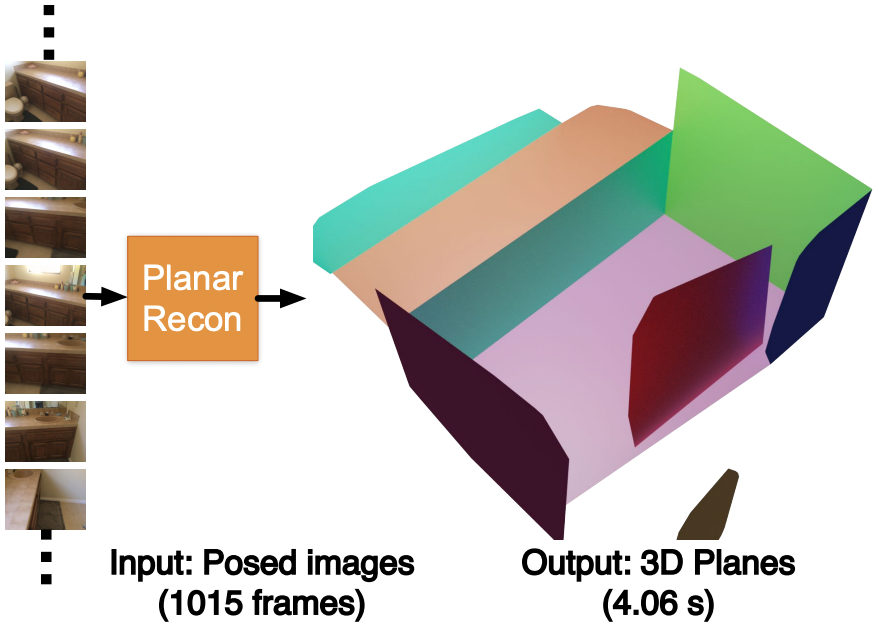
PlanarRecon: Real-time 3D Plane Detection and Reconstruction from Posed Monocular Videos
Yiming Xie, Matheus Gadelha, Fengting Yang, Xiaowei Zhou, Huaizu Jiang

Trace Match & Merge: Long-TermField-Of-View Prediction for AR Applications
Adam Viola*, Sahil Sharma*,Pankaj Bishnoi*, Matheus Gadelha, Stefano Petrangeli, Haoliang Wang, Viswanathan Swaminathan
Best paper candidate at IEEE AIVR.
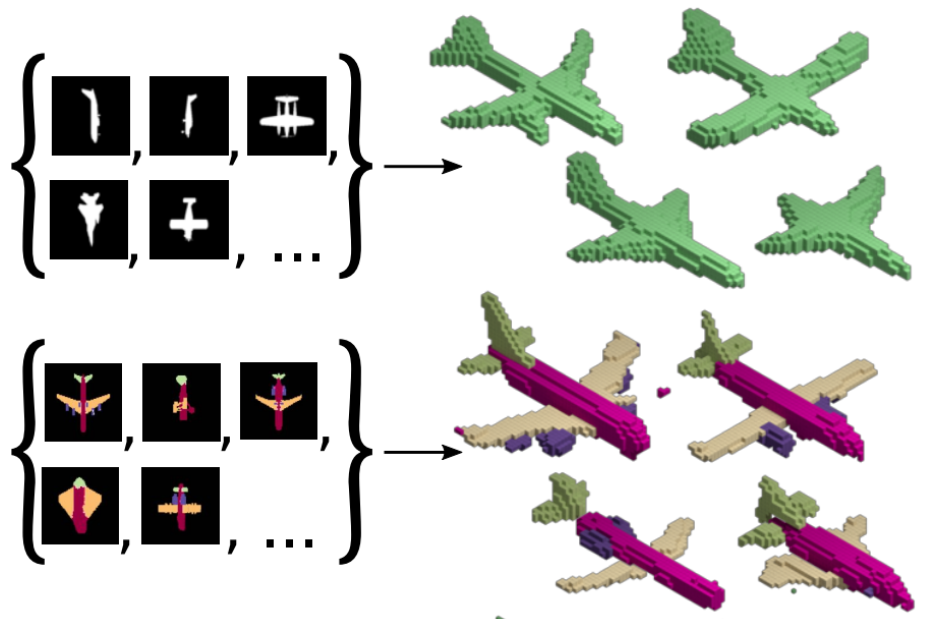
Inferring 3D Shapes from Image Collections using Adversarial Networks
Matheus Gadelha, Aartika Rai, Rui Wang, Subhransu Maji

Label-Efficient Learning on Point Clouds using Approximate Convex Decompositions
Matheus Gadelha*, Aruni RoyChowdhury*, Gopal Sharma, Evangelos Kalogerakis, Liangliang Cao, Erik Learned-Miller, Rui Wang, Subhransu Maji
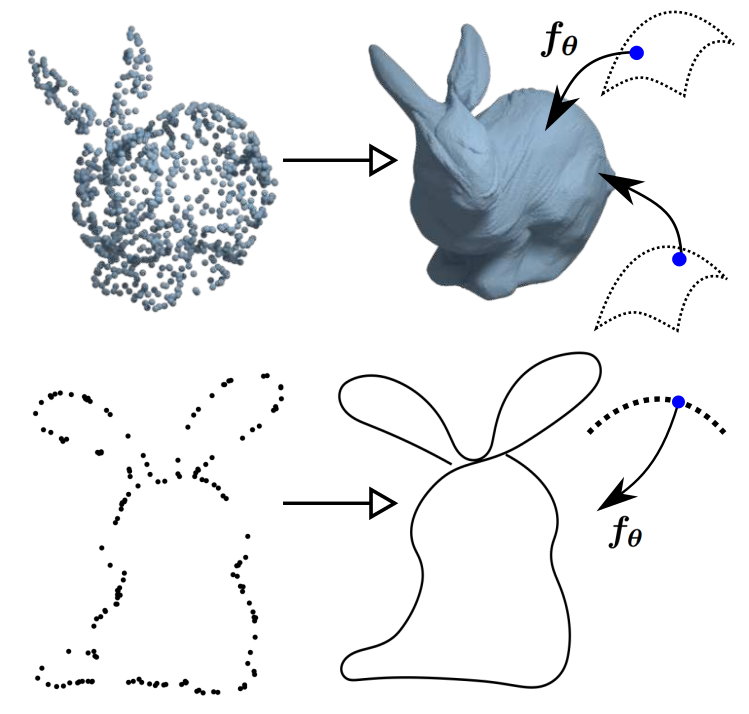
Deep Manifold Prior
Matheus Gadelha, Rui Wang, Subhransu Maji
Best poster honorable mention at NECV.

Learning Generative Models of Shape Handles
Matheus Gadelha, Giorgio Gori, Duygu Ceylan, Radomir Mech, Nathan Carr, Tamy Boubekeur, Rui Wang, Subhransu Maji
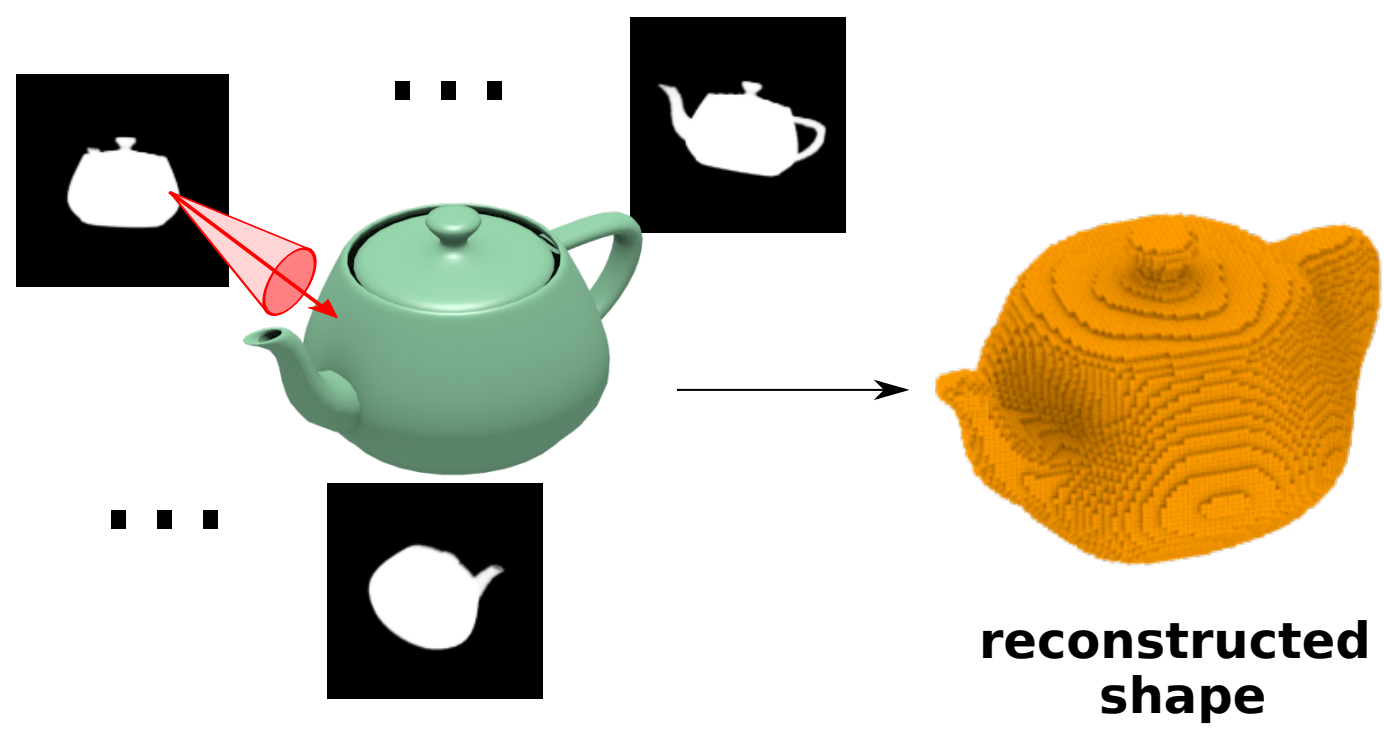
Shape Reconstruction with Differentiable Projections and Deep Priors
Matheus Gadelha, Rui Wang, Subhransu Maji

A Bayesian Perspective on the Deep Image Prior
Zezhou Cheng, Matheus Gadelha, Subhransu Maji, Daniel Sheldon

A Deeper Look at 3D Shape Classifiers
Jong-Chyi Su, Matheus Gadelha, Rui Wang, Subhransu Maji

Multiresolution Tree Networks for Point Cloud Processing
Matheus Gadelha, Rui Wang, Subhransu Maji
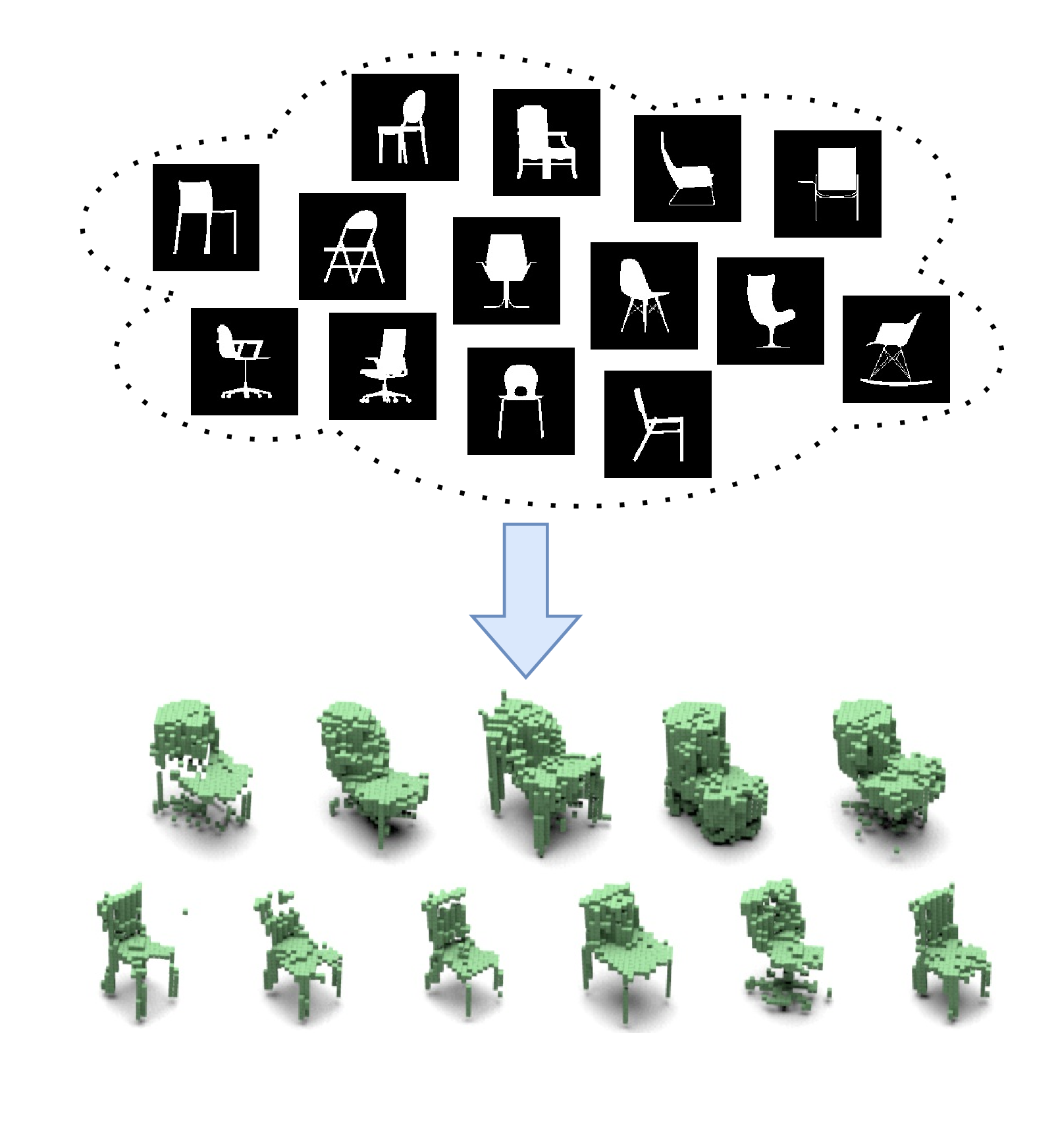
Unsupervised 3D Shape Induction from 2D Views of Multiple Objects
Matheus Gadelha, Subhransu Maji, Rui Wang

3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks
Zhaoliang Lun, Matheus Gadelha, Evangelos Kalogerakis, Subhransu Maji, Rui Wang
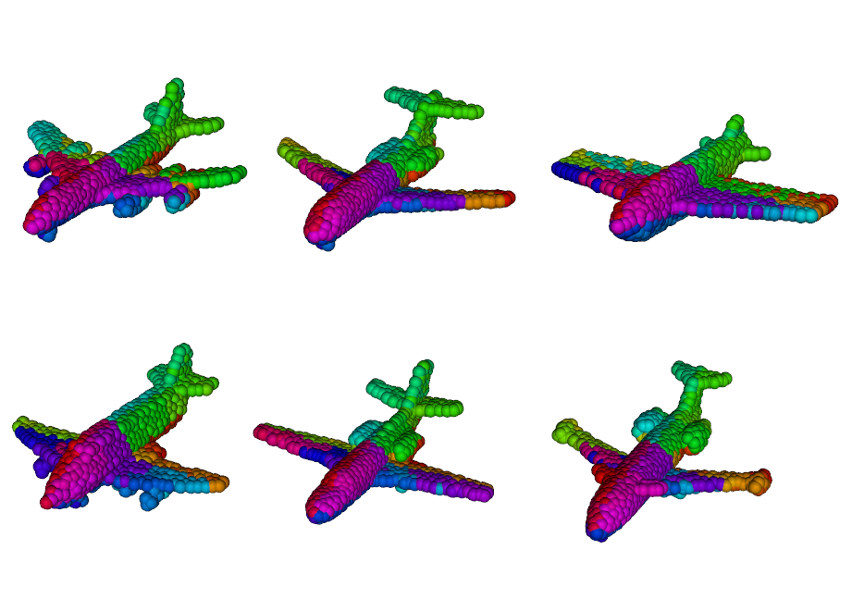
Shape Generation using Spatially Partitioned Point Clouds
Matheus Gadelha, Subhransu Maji, Rui Wang
I worked/am working as a reviewer for the following venues:
I worked/am working as AC for the following venues:
![]() Adobe.
Adobe.
Research Scientist at San Jose, CA.
June 2021 - Now.
![]() Google (Perception).
Google (Perception).
Research Intern in Amherst, MA.
Summer 2020.
![]() Adobe.
Adobe.
Research Intern at San Jose, CA
Summer 2019.
![]() Amazon.
Amazon.
Applied Scientist Intern at Pasadena, CA.
Summer 2018.
 Federal University at Rio Grande do Norte.
Federal University at Rio Grande do Norte.
Temporary Letcturer - Introduction to Algorithms and Numerical Methods.
June 2014 - June2015 .