**Directing Image Generative Models**
[Matheus Gadelha](http:/mgadelha.me)
_Latest update: June 16th, 2024_
During the last few years we have witnessed an impressive rise in the quality of computer generated imagery.
The most popular models are usually trained to perform "text-to-image" tasks -- given a text prompt, create an image that matches the description.
While being a delightful experience, it is notoriously hard to create exactly the type of imagery we have in our minds.
While already useful, I think we have just started to explore the potential of this machinery.
We need to be able to dissect and play with the content generated by those models if we want to not only make them useful for
artists and creative professionals but also to develop systems that can help us understand visual content.
This write-up explores three different ways in which our research expanded our ability to "direct" those image generative models.
First, we start by challenging what "words" mean for these systems.
Sure, they are very convenient for someone that simply wants to get some image without too much work, but it becomes increasingly
hard to express *specific* visual concepts with them.
Thus, we developed *Continuous 3D Words* -- a vocabulary of "words" that can be interpreted by image diffusion models to describe continuous
concepts like object orientation, illumination, and even the pose of deformable entities (e.g. dogs, birds, etc).
Remarkably, these concepts need very little data to be learned -- a single 3D mesh suffices.
We also went deeper into the inner workings of the large text-to-image models to modify them to create animations from 3D data + text.
Our work shows that one can manipulate the attention mechanisms while generating multiple frames to get consistent results
*without any additional training*.
Using the 3D information we can modify the backwards diffusion process to "render" coarse 3D animations into consistent videos.
In other words, we use the models as an "AI renderer".
We called this technique *Generative Rendering*.
Finally, we also explored how the same systems can be used to edit existing imagery by moving objects in a 3D-aware manner.
In this scenario, we employed off-the-shelf depth estimation to lift the image pixels to 3D where the user can perform
editing operations in a tridimensional space.
After editing is complete, associated features can be projected back to the image plane and used as guidance in a backwards
diffusion process to generate the final image.
!!!
All these works were the result of great collaborations with partners in academia and were led by
talented graduate students who spent their summer at Adobe working with us during their internships.
Please check the project pages referenced below for more information.
(##) Continuous 3D Words
!!! Tip
Project page: https://ttchengab.github.io/continuous_3d_words/
Previous work on personalizing image diffusion models usually focus on learning tokens that refer to particular entities; _i.e_.
from a small set of pictures containing a specific object one can learn a "word" that can be used to generate images of it in a text-to-image
model.
However, sometimes we are not interested in generating a specific subject, but a more general concept.
For example, it would be nice to learn a specific word that was capable of describing the position of the sun in an image.
More than that, we would like to have some _continuous control_ of the sun's position so we could precisely control the lighting of the scene.
We propose learning this concepts by using a single mesh and several renderings of it.
The learning procedure happens in two stages.
In the first stage, we render a series of images using different attribute values (e.g., illumination, pose).
We feed them into the text-to-image diffusion model to learn token embedding **[obj]** representing the single mesh used for training.
In the second stage, we add the tokens representing individual attributes into the prompt embedding.
These tokens are actually the output of a mapping network $g_\phi$ that outputs text embeddings given
human-interpretable values like the position of the sun in the sky or the object orientation.
Since $g_\phi$ is implements as an MLP, we get a _continuous_ mapping from the concept being controlled by the user to a space
that can be directly combined with a text prompt.
The two stage training allows us to better disentangle the individual attributes against **[obj]**.
At test time, attributes can be applied to different objects for text-to-image generation.
The Figure below shows some examples of the concepts we were able to control using this technique.

(##) Generative Rendering
!!! Tip
Project page: https://primecai.github.io/generative_rendering/
The main challenge in generating animations when using image diffusion models is the consistency between frames.
In this work, we propose to improve the inter-frame consistency by leveraging the existing information in a 3D animation
to control the generative process.
In other words, given a 3D animation without any texture, material or illumination, our goal is to "render" a consistent RGB
animation guided by a text prompt.
See the vide below for an example of input/output of this method.

Notice how simply generating every frame independently (second column) yields "flickery" results with visually unpleasant artifacts.
Our approach (last column) significantly ameliorates this issue *without resorting to any additional training* -- everything is
done by simple modifications to the denoising process itself.
Our system takes as input a set of UV and depths maps rendered from a user-provided animated 3D scene.
We use a depth-conditioned ControlNet to generate corresponding frames with UV correspondences to preserve the consistency.
We initialize the noise in the UV space of each object which we then render into each image.
For each backwards diffusion step, we first use extended attention for a set of keyframes and extract their pre- and post-attention features
(more information about those in the paper).
The post-attention features are projected to the UV space and unified.
Finally, all frames are generated using a weighted combination of the outputs of the extended attention with the pre-attention features of the keyframe,
and the UV-composed post-attention features from the keyframes.
(##) Diffusion Handles
!!! Tip
Project page: https://diffusionhandles.github.io/
Our goal here is simple: we want to edit object in 2D images as if they were 3D entities without actually requiring any 3D data
to perform the editing operations.
For example, consider the sunflower in the image below.

It is a trivial operation to select the sunflower and perform some in-plane rotation in your favorite image editing software.
However, things are much more challenging if we want to perform a simple operation like "out-of-plane" rotation;
_i.e_ imagine grabbing the sunflower with your hand and rotating away from the camera.
The reason this operation is much harder to accomplish is the fact that it requires some _3D reasoning_ about the image content.
The system needs to understand geometric cues in the image, deal with disocclusions and, depending of the transformation, decide existing
parts of the object become invisible due to their interaction with other scene entities.
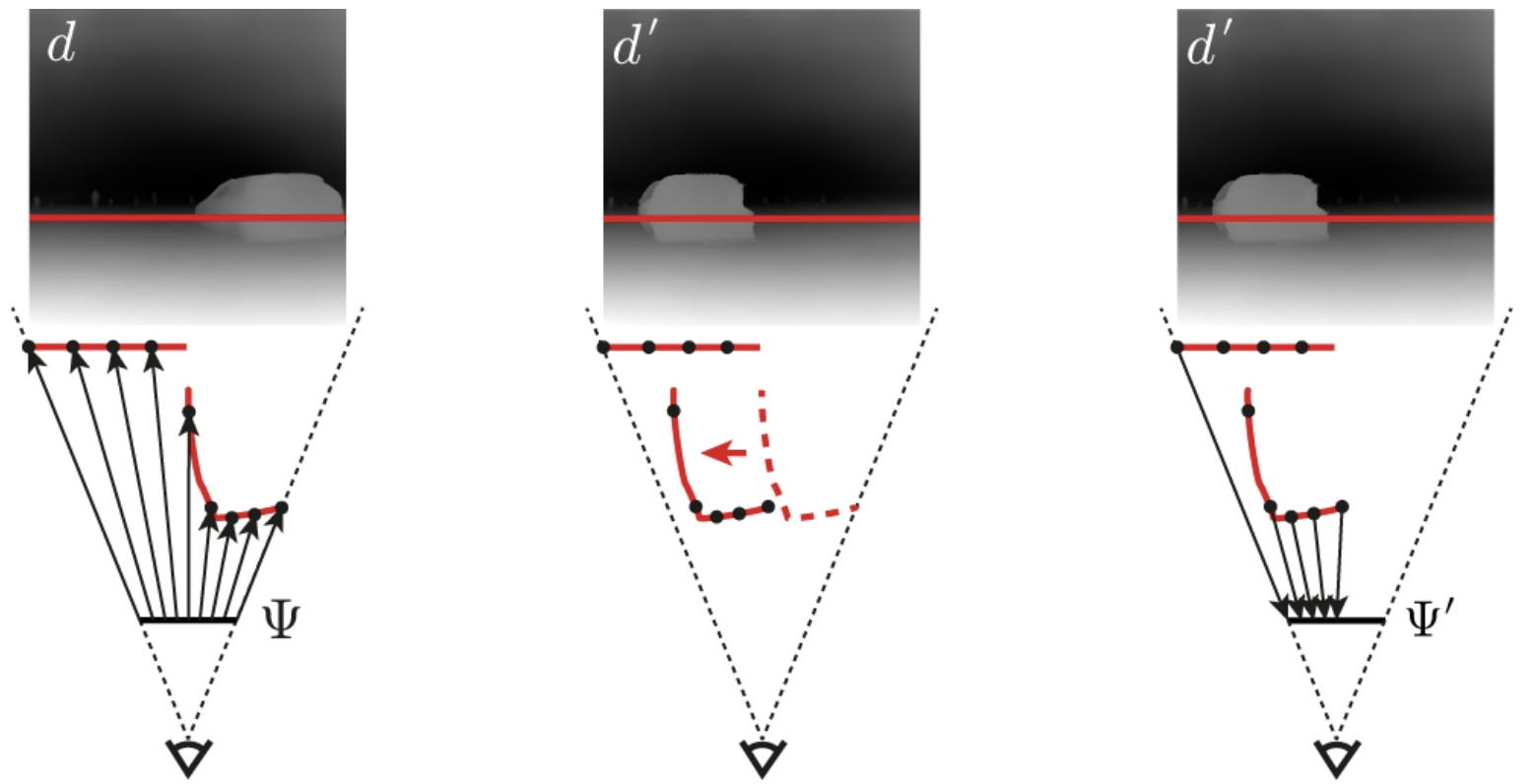
Our method consists in three main steps depicted above, from left to right.
First, the input image is reconstructed with a depth-to-image diffusion model.
Intermediate activations $\Psi$ are recorded.
Depth is estimated using a monocular depth estimator and the intermediate activations from the last step are lifted to the 3D depth surface.
A user-supplied 3D transform is applied to the depth surface and the lifted activations, creating a new
depth $d'$.
The lifted activations are projected back to the image plane creating a new 2D activation map $\Psi'$.
Finally, $d^\prime$ and $\Psi^\prime$ are used to guide the diffusion model and generate the final edited image.
Additional results are shown below.
Dotted axes correspond to the new object position and orientation.

(##) Final Remarks
Even though these papers explore very different problems, they all share a similar theme: developing tools that endow
users with fine-grained control over large text-to-image generative models.
These are important not only to enable useful applications, but also to deepen our understanding of how these models work.
More importantly, none of the methods described above requires large scale training.
Their main insights do not lie in leveraging bigger and bigger datasets, but in investigating how these models behave
and using this knowledge to build interesting applications.
Finally, it seems that these works are representative of a noticeable trend where 3D is being promoted to first-class citizen
in image and video manipulation.
Few years ago, 3D representations were a scary topic that was restricted to specialists and seasoned professionals.
As image generative models improved, many ask the question: "why 3D is even needed?".
I think at this point it is clear that some 3D representation is paramount for _controlling_ which type of content we generate.
While 3D assets may not be the final goal in many of these processes, users will benefit
from interacting with systems that can _reason_ in 3D even when creating images.